Capítulo 5 Métodos modelo-agnósticos
Separar las explicaciones del modelo de aprendizaje automático (= métodos de interpretación independientes del modelo) tiene algunas ventajas (Ribeiro, Singh y Guestrin 201625). La gran ventaja de los métodos de interpretación independientes del modelo sobre los específicos del modelo es su flexibilidad. Los desarrolladores de aprendizaje automático pueden usar cualquier modelo de aprendizaje automático que deseen cuando los métodos de interpretación se pueden aplicar a cualquier modelo. Todo lo que se basa en una interpretación de un modelo de aprendizaje automático, como una interfaz gráfica o de usuario, también se vuelve independiente del modelo de aprendizaje automático subyacente. Por lo general, no solo se evalúa uno, sino que se evalúan muchos tipos de modelos de aprendizaje automático para resolver una tarea, y cuando se comparan modelos en términos de interpretabilidad, es más fácil trabajar con explicaciones independientes del modelo, ya que se puede usar el mismo método para cualquier tipo de modelo.
Una alternativa a los métodos de interpretación independientes del modelo es usar solo modelos interpretables, que a menudo tiene la gran desventaja de que se pierde el rendimiento predictivo en comparación con otros modelos de aprendizaje automático y se limita a un tipo de modelo. La otra alternativa es utilizar métodos de interpretación específicos del modelo. La desventaja de esto es que también lo vincula a un tipo de modelo y será difícil cambiar a otra cosa.
Los aspectos deseables de un sistema de explicación modelo-agnóstico son (Ribeiro, Singh y Guestrin 2016):
- Flexibilidad del modelo: El método de interpretación puede funcionar con cualquier modelo de aprendizaje automático, como random forest y redes neuronales profundas.
- Flexibilidad de explicación: No está limitado a una cierta forma de explicación. En algunos casos, puede ser útil tener una fórmula lineal, en otros casos, un gráfico con características importantes.
- Flexibilidad de representación: El sistema de explicación debería poder utilizar una representación de características diferente como el modelo que se explica. Para un clasificador de texto que usa vectores abstractos de incrustación de palabras, podría ser preferible usar la presencia de palabras individuales para la explicación.
La fotografía más grande
Echemos un vistazo de alto nivel a la interpretabilidad agnóstica del modelo. Capturamos el mundo mediante la recopilación de datos y lo resumimos aún más al aprender a predecir los datos (para la tarea) con un modelo de aprendizaje automático. La interpretabilidad es solo otra capa en la parte superior que ayuda a los humanos a comprender.
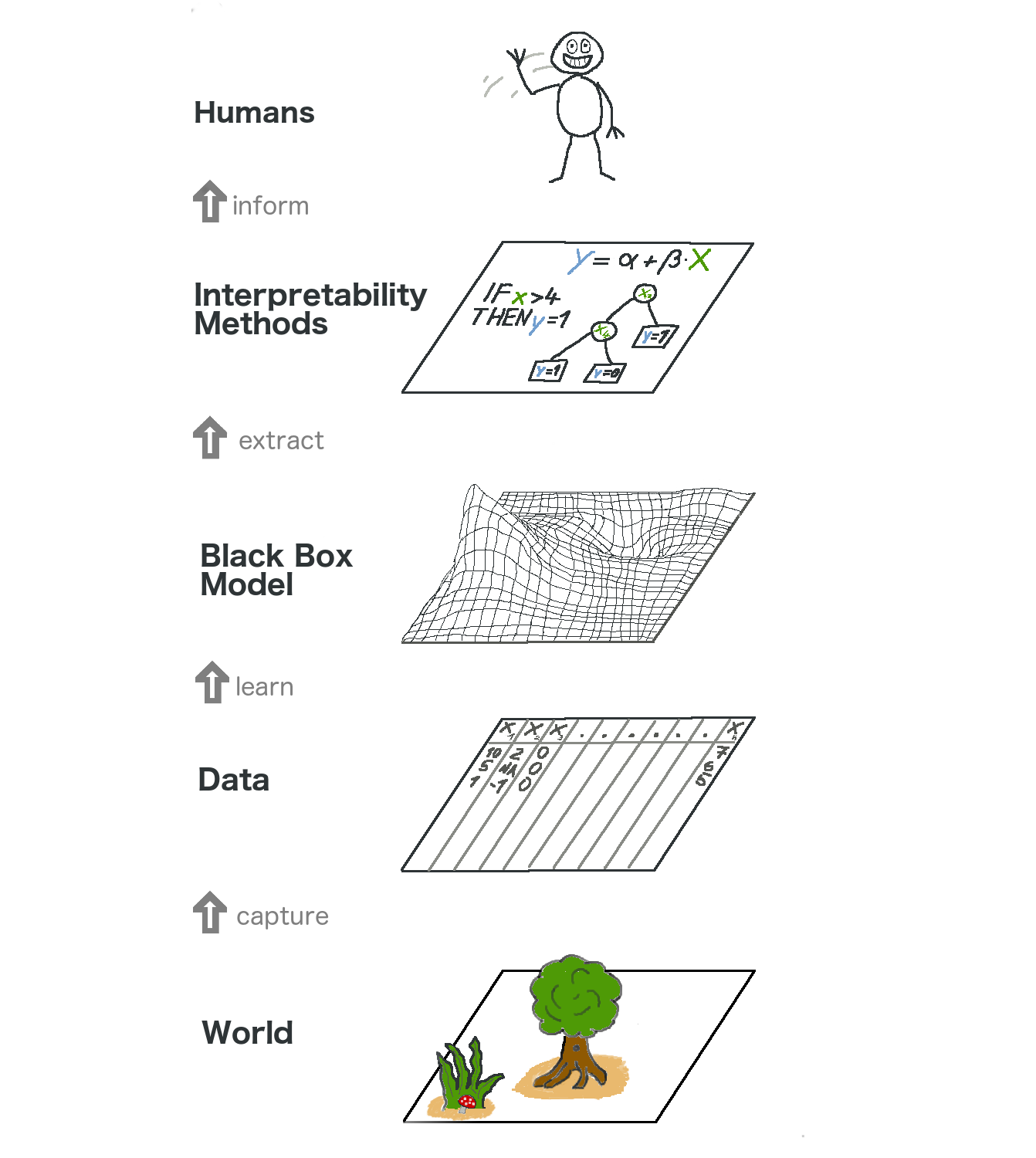
FIGURA 5.1: El panorama general del aprendizaje automático explicable. El mundo real atraviesa muchas capas antes de llegar al humano en forma de explicaciones.
La capa más baja es el Mundo. Esto podría ser literalmente la naturaleza misma, como la biología del cuerpo humano y cómo reacciona a la medicación, pero también cosas más abstractas como el mercado inmobiliario. Esta capa contiene todo lo que se puede observar y es de interés. En definitiva, queremos aprender algo sobre el mundo e interactuar con él.
La segunda capa es la capa Datos. Tenemos que digitalizar el mundo para que sea procesable para las computadoras y también para almacenar información. La capa de datos contiene cualquier cosa, desde imágenes, textos, datos tabulares, etc.
Al ajustar modelos de aprendizaje automático basados en la capa de datos, obtenemos la capa de modelos de caja negra. Los algoritmos de aprendizaje automático aprenden con datos del mundo real para hacer predicciones o encontrar estructuras.
Por encima de la capa de modelos de caja negra se encuentra la capa Métodos de interpretación, que nos ayuda a lidiar con la opacidad de los modelos de aprendizaje automático. ¿Cuáles fueron las características más importantes para un diagnóstico particular? ¿Por qué una transacción financiera se clasificó como fraude?
La última capa está ocupada por un Humano. ¡Mira! ¡Te saluda porque estás leyendo este libro y estás ayudando a proporcionar mejores explicaciones para los modelos de caja negra! Los humanos son, en última instancia, los consumidores de las explicaciones.
Esta abstracción de varias capas también ayuda a comprender las diferencias en los enfoques entre los estadísticos y los profesionales del aprendizaje automático. Los estadísticos se ocupan de la capa de datos, como planificar ensayos clínicos o diseñar encuestas. Se saltan la capa del Modelo de caja negra y van directamente a la capa Métodos de interpretación. Los especialistas en aprendizaje automático también se ocupan de la capa de datos, como recolectar muestras etiquetadas de imágenes de cáncer de piel o rastrear Wikipedia. Luego entrenan un modelo de aprendizaje automático de caja negra. Se omite la capa Métodos de interpretación y los humanos se ocupan directamente de las predicciones del modelo de caja negra. Es genial que el aprendizaje automático interpretable fusione el trabajo de estadísticos y especialistas en aprendizaje automático.
Por supuesto, este gráfico no captura todo: Los datos pueden provenir de simulaciones. Los modelos de caja negra también generan predicciones que podrían ni siquiera llegar a los humanos, sino que solo suministran otras máquinas, etc. Pero, en general, es una abstracción útil comprender cómo la interpretabilidad se convierte en esta nueva capa además de los modelos de aprendizaje automático.
Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. “Model-agnostic interpretability of machine learning.” ICML Workshop on Human Interpretability in Machine Learning. (2016).↩