5.7 Sustituto local (LIME)
Los modelos sustitutos locales son modelos interpretables que se utilizan para explicar las predicciones individuales de los modelos de aprendizaje automático de caja negra. En el artículo original, los autores proponen36 una implementación concreta de modelos sustitutos locales. Los modelos sustitutos están entrenados para aproximar las predicciones del modelo de caja negra subyacente. En lugar de entrenar un modelo sustituto global, LIME se enfoca en entrenar modelos sustitutos locales para explicar las predicciones individuales.
La idea es bastante intuitiva. Primero, olvida los datos de entrenamiento e imagina que solo tienes el modelo de caja negra donde puedes ingresar puntos de datos y obtener las predicciones del modelo. Puedes ingresar puntos de datos en la caja tantas veces como quieras. Tu objetivo es comprender por qué el modelo de aprendizaje automático hizo una cierta predicción. LIME prueba lo que sucede con las predicciones cuando proporcionas variaciones de tus datos al modelo de aprendizaje automático. LIME genera un nuevo conjunto de datos que consta de muestras permutadas y las correspondientes predicciones del modelo de caja negra. En este nuevo conjunto de datos, LIME luego entrena un modelo interpretable, que se pondera por la proximidad de las instancias muestreadas a la instancia de interés. El modelo interpretable puede ser cualquier modelo interpretable, por ejemplo Lasso o un árbol de decisión. El modelo aprendido debería ser una buena aproximación de las predicciones del modelo de aprendizaje automático en forma local, no necesariamente en forma global. Este tipo de precisión también se llama fidelidad local.
Matemáticamente, los modelos sustitutos locales con restricción de interpretabilidad se pueden expresar de la siguiente manera:
\[\text{explanation}(x)=\arg\min_{g\in{}G}L(f,g,\pi_x)+\Omega(g)\]
El modelo de explicación para la observación x es el modelo g (por ejemplo, modelo de regresión lineal) que minimiza la pérdida L (por ejemplo, error cuadrático medio), que mide qué tan cerca está la explicación de la predicción del modelo original f (por ejemplo, un modelo xgboost), mientras que la complejidad del modelo \(\Omega(g)\) se mantiene baja (por ejemplo, prefieres menos características). G es la familia de posibles explicaciones, por ejemplo, todos los posibles modelos de regresión lineal. La medida de proximidad \(\pi_x\) define qué tan grande es el vecindario alrededor de la instancia x que consideramos para la explicación. En la práctica, LIME solo optimiza la parte de pérdida. El usuario tiene que determinar la complejidad p, seleccionando el número máximo de características que puede usar el modelo de regresión lineal.
La receta para entrenar modelos locales sustitutos:
- Selecciona tu instancia de interés para la que deseas tener una explicación de tu predicción de caja negra.
- Perturba tu conjunto de datos y obtén las predicciones de caja negra para estos nuevos puntos.
- Pondera las nuevas muestras según su proximidad a la instancia de interés.
- Entrena un modelo ponderado e interpretable en el conjunto de datos con las variaciones.
- Explica la predicción interpretando el modelo local.
En las implementaciones actuales en R y Python, por ejemplo, la regresión lineal se puede elegir como sustituto interpretable. De antemano, debes seleccionar K, la cantidad de características que deseas tener en tu modelo interpretable. Cuanto más baja es la K, más fácil es interpretar el modelo. Una K más alta potencialmente produce modelos con mayor fidelidad. Existen varios métodos para entrenar modelos con exactamente K características. Una buena opción es Lasso. Un modelo Lasso con un alto parámetro de regularización \(\lambda\) produce un modelo sin ninguna característica. Al volver a entrenar los modelos Lasso con una disminución lenta de \(\lambda\), una tras otra, las características obtienen estimaciones de peso que difieren de cero. Si hay K características en el modelo, has alcanzado la cantidad deseada de características. Otras estrategias son la selección de características hacia adelante o hacia atrás. Esto significa que comienza con el modelo completo (= que contiene todas las características) o con un modelo con solo el intercepto y luego prueba qué característica brindaría la mayor mejora cuando se agrega o elimina, hasta que se alcanza un modelo con K características.
¿Cómo se obtienen las variaciones de los datos? Esto depende del tipo de datos, que pueden ser texto, imagen o datos tabulares. Para texto e imágenes, la solución es activar o desactivar palabras simples o superpíxeles. En el caso de los datos tabulares, LIME crea nuevas muestras al perturbar cada característica individualmente, dibujando a partir de una distribución normal con desviación estándar y media tomada de la característica.
5.7.1 LIME para datos tabulares
Los datos tabulares son datos que vienen en tablas, cada fila representa una instancia y cada columna una característica. Las muestras de LIME no se toman alrededor de la instancia de interés, sino del centro de masa de los datos de entrenamiento, lo cual es problemático. Pero aumenta la probabilidad de que el resultado para algunas de las predicciones de puntos de muestra difiera del punto de datos de interés y que LIME pueda aprender al menos alguna explicación.
Es mejor explicar visualmente cómo funciona el muestreo y el entrenamiento en modelos locales:
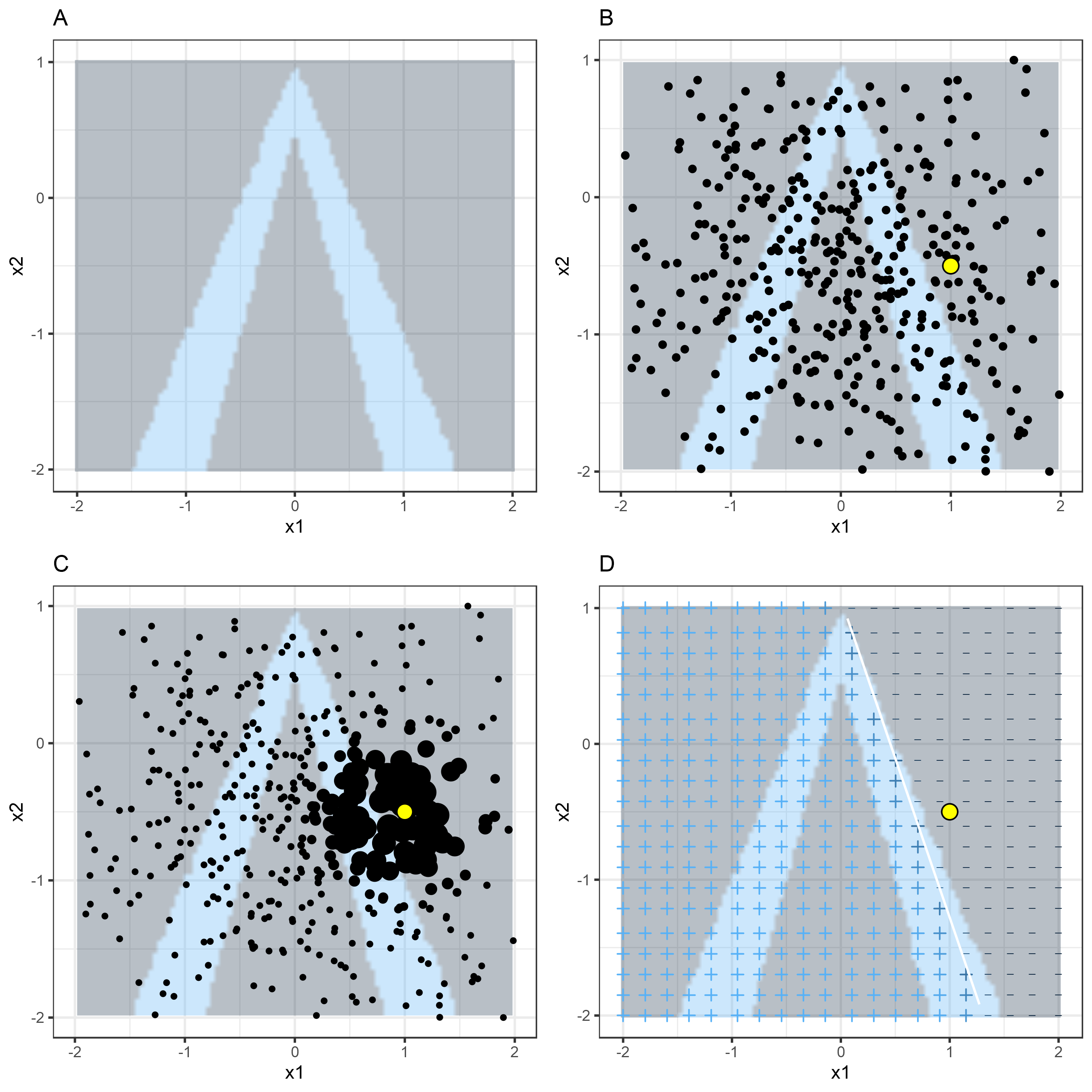
FIGURA 5.32: Algoritmo LIME para datos tabulares. A) Las predicciones aleatorias del random forest dan características x1 y x2. Clases previstas: 1 (oscuro) o 0 (claro). B) Instancia de interés (punto grande) y datos muestreados de una distribución normal (puntos pequeños). C) Asigna un mayor peso a los puntos cercanos a la instancia de interés. D) Los signos de la cuadrícula muestran las clasificaciones del modelo aprendido localmente de las muestras ponderadas. La línea blanca marca el límite de decisión (P (clase = 1) = 0.5).
Como siempre, el diablo está en los detalles. Definir un vecindario significativo alrededor de un punto es difícil. LIME actualmente utiliza un smoothing kernel (núcleo exponencial de suavizado) para definir el vecindario. Es una función que toma dos instancias de datos y devuelve una medida de proximidad. El ancho del kernel determina qué tan grande es el vecindario: Un ancho de kernel pequeño significa que una instancia debe estar muy cerca para influir en el modelo local, un ancho de kernel más grande significa que las instancias que están más lejos también influyen en el modelo. Si observas la implementación de Python LIME (file lime/lime_tabular.py) verás que utiliza un kernel exponencial (en los datos normalizados) y el ancho del kernel es 0,75 veces la raíz cuadrada del número de columnas de los datos de entrenamiento. Parece una línea de código inocente, pero es como un elefante sentado en tu sala de estar al lado de la porcelana que te dieron tus abuelos. El gran problema es que no tenemos una buena manera de encontrar el mejor núcleo o ancho. ¿Y de dónde viene el 0.75? En ciertos escenarios, puedes cambiar fácilmente tu explicación cambiando el ancho del núcleo, como se muestra en la siguiente figura:
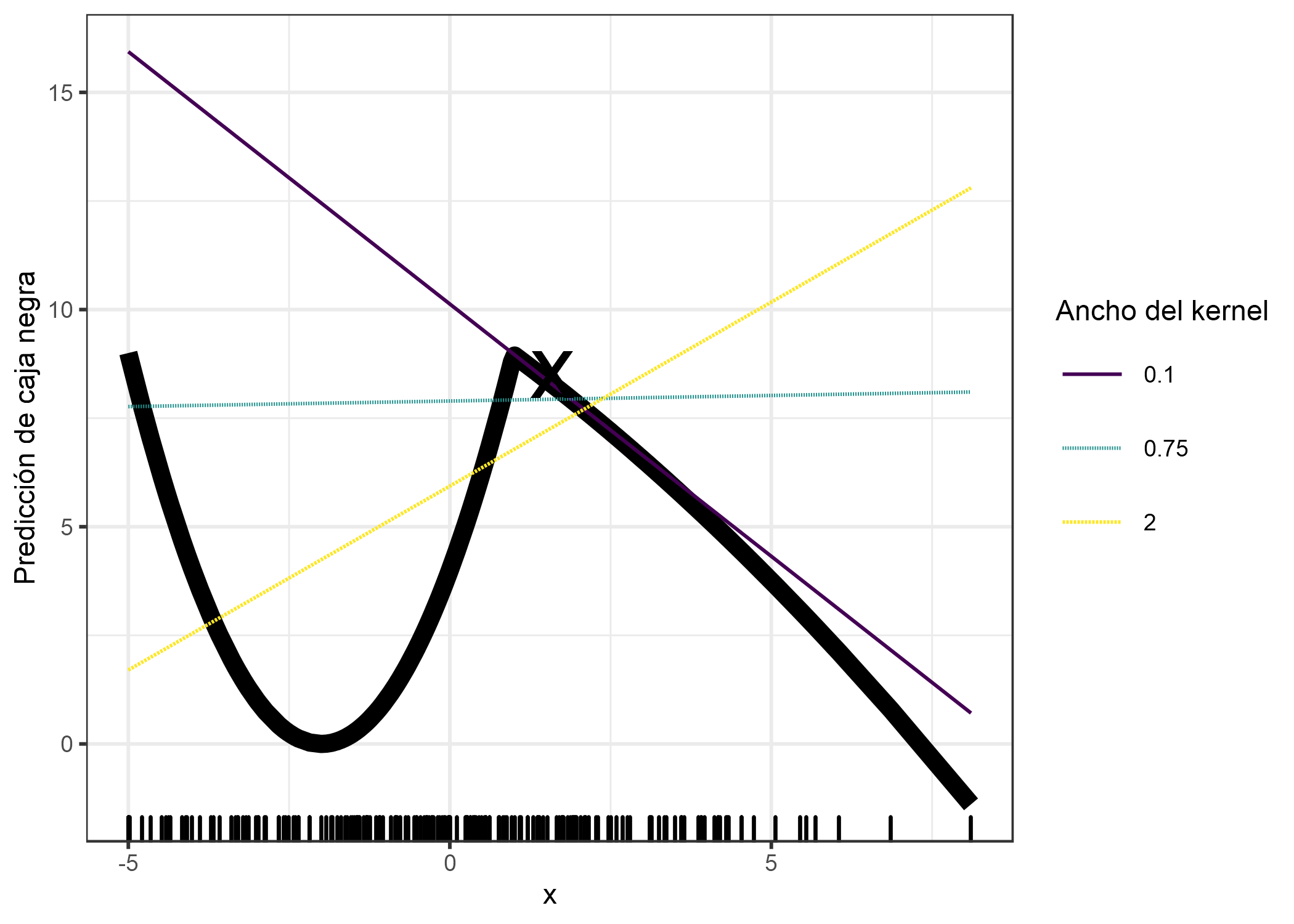
FIGURA 5.33: Explicación de la predicción de la instancia x = 1.6. Las predicciones del modelo de caja negra que dependen de una sola característica se muestran como una línea gruesa y se muestra la distribución de los datos con alfombras. Se calculan tres modelos sustitutos locales con diferentes anchos de núcleo. El modelo de regresión lineal resultante depende del ancho del kernel: ¿La característica tiene un efecto negativo, positivo o nulo para x = 1.6?
El ejemplo muestra solo una característica. Empeora en espacios de características de alta dimensión. Tampoco está muy claro si la medida de distancia debe tratar todas las características por igual. ¿Una unidad de distancia para la característica x1 es idéntica a una unidad para la característica x2? Las medidas de distancia son bastante arbitrarias y las distancias en diferentes dimensiones (también conocidas como características) podrían no ser comparables en absoluto.
5.7.1.1 Ejemplo
Veamos un ejemplo concreto. Volvemos a los datos de alquiler de bicicletas y convertimos el problema de predicción en uno de clasificación: Después de tener en cuenta la tendencia de que el alquiler de bicicletas se ha vuelto más popular con el tiempo, queremos saber en un día determinado si el número de bicicletas alquiladas será superior o inferior a la línea de tendencia. También puedes interpretar “arriba” como estar por encima del número promedio de bicicletas, pero ajustado por la tendencia.
Primero entrenamos un random forest con 100 árboles en la tarea de clasificación. ¿En qué día el número de bicicletas de alquiler estará por encima del promedio libre de tendencias, según la información del clima y el calendario?
Las explicaciones se crean con 2 características. Los resultados de los escasos modelos lineales locales entrenados para dos instancias con diferentes clases predichas:
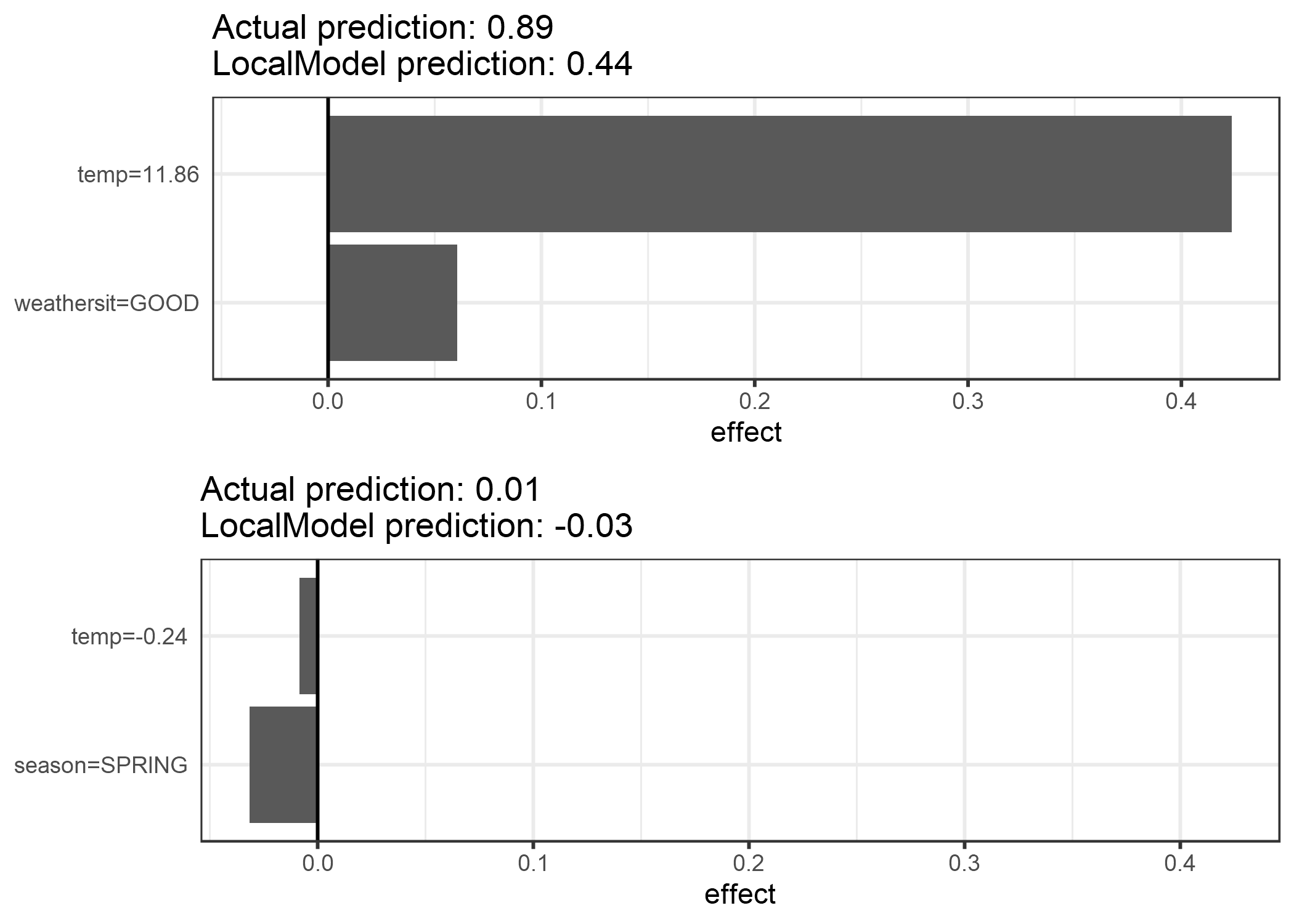
FIGURA 5.34: Explicaciones LIME para dos instancias del conjunto de datos de alquiler de bicicletas. La temperatura más cálida y la buena situación climática tienen un efecto positivo en la predicción. El eje x muestra el efecto de la entidad: el peso multiplicado por el valor real de la entidad.
De la figura queda claro que es más fácil interpretar características categóricas que características numéricas. Una solución es transformar las variables numéricas en categóricas.
5.7.2 LIME para texto
LIME para texto difiere de LIME para datos tabulares. Las variaciones de los datos se generan de manera diferente: A partir del texto original, se crean nuevos textos eliminando al azar palabras del texto original. El conjunto de datos se representa con características binarias para cada palabra. Una característica es 1 si se incluye la palabra correspondiente y 0 si se ha eliminado.
5.7.2.1 Ejemplo
En este ejemplo, clasificamos comentarios de YouTube como spam o normal.
El modelo de caja negra es un árbol de decisión profundo entrenado en la matriz de palabras del documento. Cada comentario es un documento (= una fila) y cada columna es el número de apariciones de una palabra dada. Los árboles de decisión cortos son fáciles de entender, pero en este caso el árbol es muy profundo. También en lugar de este árbol podría haber habido una red neuronal recurrente o una SVM entrenada en incrustaciones de palabras (vectores abstractos). Veamos los dos comentarios de este conjunto de datos y las clases correspondientes (1 para spam, 0 para comentario normal):
| CONTENT | CLASS | |
|---|---|---|
| 267 | PSY is a good guy | 0 |
| 173 | For Christmas Song visit my channel! ;) | 1 |
El siguiente paso es crear algunas variaciones de los conjuntos de datos utilizados en un modelo local. Por ejemplo, algunas variaciones de uno de los comentarios:
| For | Christmas | Song | visit | my | channel! | ;) | prob | weight | |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0.17 | 0.57 |
| 3 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0.17 | 0.71 |
| 4 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0.99 | 0.71 |
| 5 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0.99 | 0.86 |
| 6 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0.17 | 0.57 |
Cada columna corresponde a una palabra en la oración.
Cada fila es una variación, 1 significa que la palabra es parte de esta variación y 0 significa que la palabra ha sido eliminada.
La oración correspondiente para una de las variaciones es “Christmas Song visit my ;)”.
La columna “prob” muestra la probabilidad pronosticada de spam para cada una de las variaciones de la oración.
La columna “weight” muestra la proximidad de la variación a la oración original, calculada como 1 menos la proporción de palabras que se eliminaron, por ejemplo, si se eliminó 1 de 7 palabras, la proximidad es 1 - 1/7 = 0.86.
Aquí están las dos oraciones (una no deseada, una no deseada) con sus estimaciones de pesos locales encontradas por el algoritmo LIME:
| case | label_prob | feature | feature_weight |
|---|---|---|---|
| 1 | 0.1701170 | good | 0.000000 |
| 1 | 0.1701170 | a | 0.000000 |
| 1 | 0.1701170 | is | 0.000000 |
| 2 | 0.9939024 | channel! | 6.180747 |
| 2 | 0.9939024 | For | 0.000000 |
| 2 | 0.9939024 | ;) | 0.000000 |
La palabra “channel” indica una alta probabilidad de spam. Para el comentario que no es spam, no se estimó un peso distinto de cero, porque no importa qué palabra se elimine, la clase predicha sigue siendo la misma.
5.7.3 LIME para imágenes
Esta sección fue escrita por Verena Haunschmid.
LIME para imágenes funciona de manera diferente que LIME para datos tabulares y texto. Intuitivamente, no tendría mucho sentido perturbar píxeles individuales, ya que muchos más de un píxel contribuyen a una clase. El cambio aleatorio de píxeles individuales probablemente no cambiaría mucho las predicciones. Por lo tanto, las variaciones de las imágenes se crean segmentando la imagen en “superpíxeles” y activando o desactivando los superpíxeles. Los superpíxeles son píxeles interconectados con colores similares y se pueden apagar reemplazando cada píxel con un color definido por el usuario, como el gris. El usuario también puede especificar una probabilidad de apagar un superpíxel en cada permutación.
5.7.3.1 Ejemplo
Como el cálculo de las explicaciones de las imágenes es bastante lento, el paquete Lime R contiene un ejemplo precalculado que también usaremos para mostrar el resultado del método.
Las explicaciones se pueden mostrar directamente en las muestras de imagen.
Como podemos tener varias etiquetas predichas por imagen (ordenadas por probabilidad), podemos explicar los principales n_labels.
Para la siguiente imagen, las 3 predicciones principales fueron guitarra eléctrica; guitarra acustica; y labrador.

FIGURA 5.35: Explicaciones LIME para las 3 clases principales de clasificación de imágenes realizadas por la red neuronal Inception de Google. El ejemplo está tomado del artículo LIME (Ribeiro et al. ., 2016).
La predicción y explicación en el primer caso son muy razonables. La primera predicción de guitarra eléctrica es, por supuesto, incorrecta, pero la explicación nos muestra que la red neuronal todavía se comportó razonablemente porque la parte de la imagen identificada sugiere que podría tratarse de una guitarra eléctrica.
5.7.4 Ventajas
Incluso si reemplazas el modelo de aprendizaje automático subyacente, aún puedes usar el mismo modelo local e interpretable para la explicación. Supongamos que las personas que miran las explicaciones entienden mejor los árboles de decisión. Debido a que usas modelos sustitutos locales, usas árboles de decisión como explicaciones sin tener que usar un árbol de decisión para hacer las predicciones. Por ejemplo, puedes usar una SVM. Y si resulta que un modelo xgboost funciona mejor, puedes reemplazar el SVM y aún usarlo como árbol de decisión para explicar las predicciones.
Los modelos sustitutos locales se benefician de la literatura y la experiencia de entrenamiento e interpretación de modelos interpretables.
Cuando se usa Lasso o árboles cortos, las explicaciones resultantes son cortas (= selectivas) y posiblemente contrastantes. Por lo tanto, hacen explicaciones amigables para los humanos. Es por eso que veo LIME más en aplicaciones donde el destinatario de la explicación es un laico o alguien con muy poco tiempo. No es suficiente para las atribuciones completas, por lo que no veo LIME en escenarios de cumplimiento en los que legalmente se le puede exigir que explique completamente una predicción. También para depurar modelos de aprendizaje automático, es útil tener todas las razones en lugar de algunas.
LIME es uno de los pocos métodos que funciona para datos tabulares, texto e imágenes.
La medida de fidelidad (qué tan bien el modelo interpretable se aproxima a las predicciones de caja negra) nos da una buena idea de cuán confiable es el modelo interpretable para explicar las predicciones de caja negra en la vecindad de la instancia de datos de interés.
LIME se implementa en Python (biblioteca lime) y R (paquete lime y paquete iml) y es muy fácil de usar.
Las explicaciones creadas con modelos sustitutos locales pueden usar otras características (interpretables) que el modelo original en el que se entrenó. Por supuesto, estas características interpretables deben derivarse de las instancias de datos. Un clasificador de texto puede confiar en la inserción de palabras abstractas como características, pero la explicación puede basarse en la presencia o ausencia de palabras en una oración. Un modelo de regresión puede basarse en una transformación no interpretable de algunos atributos, pero las explicaciones se pueden crear con los atributos originales. Por ejemplo, el modelo de regresión podría recibir entrenamiento sobre los componentes de un análisis de componentes principales (PCA) de las respuestas a una encuesta, pero LIME podría recibir entrenamiento sobre las preguntas originales de la encuesta. El uso de características interpretables para LIME puede ser una gran ventaja sobre otros métodos, especialmente cuando el modelo fue entrenado con características no interpretables.
5.7.5 Desventajas
La definición correcta del vecindario es un gran problema sin resolver cuando se utiliza LIME con datos tabulares. En mi opinión, es el mayor problema con LIME y la razón por la que recomendaría usar LIME solo con mucho cuidado. Para cada aplicación, debes probar diferentes configuraciones de kernel y ver por tí mismo si las explicaciones tienen sentido. Desafortunadamente, este es el mejor consejo que puedo dar para encontrar buenos anchos de kernel.
El muestreo podría mejorarse en la implementación actual de LIME. Los puntos de datos se muestrean a partir de una distribución gaussiana, ignorando la correlación entre las características. Esto puede conducir a puntos de datos poco probables que luego se pueden utilizar para aprender modelos de explicación local.
La complejidad del modelo de explicación debe definirse de antemano. Esto es solo una pequeña queja, porque al final el usuario siempre tiene que definir el punto que quiere entre fidelidad y escasez.
Otro gran problema es la inestabilidad de las explicaciones. En un artículo37 los autores mostraron que las explicaciones de dos puntos muy cercanos variaban mucho en un entorno simulado. Además, en mi experiencia, si repites el proceso de muestreo, las explicaciones que salen pueden ser diferentes. La inestabilidad significa que es difícil confiar en las explicaciones, por lo que debes ser muy crítico.
Conclusión: Los modelos sustitutos locales, con LIME como una implementación concreta, son muy prometedores. Pero el método todavía está en fase de desarrollo y muchos problemas deben resolverse antes de que pueda aplicarse de forma segura.
Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. “Why should I trust you?: Explaining the predictions of any classifier.” Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. ACM (2016).↩
Alvarez-Melis, David, and Tommi S. Jaakkola. “On the robustness of interpretability methods.” arXiv preprint arXiv:1806.08049 (2018).↩