5.6 Sustituto global
Un modelo sustituto global es un modelo interpretable que está entrenado para aproximar las predicciones de un modelo de caja negra. Podemos sacar conclusiones sobre el modelo de caja negra interpretando el modelo sustituto. ¡Resolvemos la interpretación del aprendizaje automático usando más aprendizaje automático!
5.6.1 Teoría
Los modelos sustitutos también se utilizan en ingeniería: Si un resultado de interés es costoso, requiere mucho tiempo o es difícil de medir (por ejemplo, porque proviene de una compleja simulación por computadora), se puede utilizar un modelo sustituto barato y rápido del resultado. La diferencia entre los modelos sustitutos utilizados en ingeniería y en el aprendizaje automático interpretable es que el modelo subyacente es un modelo de aprendizaje automático (no una simulación) y que el modelo sustituto debe ser interpretable. El propósito de los modelos sustitutos (interpretables) es aproximar las predicciones del modelo subyacente con la mayor precisión posible y ser interpretables al mismo tiempo. La idea de modelos sustitutos se puede encontrar bajo diferentes nombres: Modelo de aproximación, metamodelo, modelo de superficie de respuesta, emulador, …
Sobre la teoría: En realidad, no se necesita mucha teoría para comprender los modelos sustitutos. Queremos aproximar nuestra función de predicción de caja negra f lo más cerca posible con la función de predicción de modelo sustituto g, bajo la restricción de que g es interpretable. Para la función g se puede utilizar cualquier modelo interpretable, por ejemplo, del capítulo de modelos interpretables.
Por ejemplo un modelo lineal:
\[g(x)=\beta_0+\beta_1{}x_1{}+\ldots+\beta_p{}x_p\]
O un árbol de decisión:
\[g(x)=\sum_{m=1}^Mc_m{}I\{x\in{}R_m\}\]
El entrenamiento de un modelo sustituto es un método independiente del modelo, ya que no requiere ninguna información sobre el funcionamiento interno del modelo de caja negra, solo es necesario el acceso a los datos y la función de predicción. Si el modelo de aprendizaje automático subyacente se reemplazó por otro, aún podrías usar el método sustituto. La elección del tipo de modelo de caja negra y del tipo de modelo sustituto está desacoplada.
Realiza los siguientes pasos para obtener un modelo sustituto:
- Selecciona un conjunto de datos X. Este puede ser el mismo conjunto de datos que se utilizó para entrenar el modelo de caja negra o un nuevo conjunto de datos de la misma distribución. Incluso podrías seleccionar un subconjunto de datos o una cuadrícula de puntos, dependiendo de tu aplicación.
- Para el conjunto de datos X seleccionado, obtén las predicciones del modelo de caja negra.
- Selecciona un tipo de modelo interpretable (modelo lineal, árbol de decisión, …).
- Entrena el modelo interpretable en el conjunto de datos X y sus predicciones.
- ¡Felicidades! Ahora tienes un modelo sustituto.
- Mide qué tan bien el modelo sustituto replica las predicciones del modelo de caja negra.
- Interpreta el modelo sustituto.
Puedes encontrar enfoques para los modelos sustitutos que tienen algunos pasos adicionales o difieren un poco, pero la idea general suele ser como se describe aquí.
Una forma de medir qué tan bien el sustituto replica el modelo de caja negra es la medida de R cuadrado:
\[R^2=1-\frac{SSE}{SST}=1-\frac{\sum_{i=1}^n(\hat{y}_*^{(i)}-\hat{y}^{(i)})^2}{\sum_{i=1}^n(\hat{y}^{(i)}-\bar{\hat{y}})^2}\]
donde \(\hat{y}_*^{(i)}\) es la predicción para la i-ésima instancia del modelo sustituto, \(\hat{y}^{(i)}\) la predicción del modelo de caja negra y \(\bar{\hat{y}}\) la media de las predicciones del modelo de caja negra. SSE significa error de suma de cuadrados y SST para total de suma de cuadrados. La medida de R cuadrado se puede interpretar como el porcentaje de varianza que captura el modelo sustituto. Si R-cuadrado está cerca de 1 (= SSE bajo), entonces el modelo interpretable se aproxima muy bien al comportamiento del modelo de caja negra. Si el modelo interpretable está muy cerca, es posible que desee reemplazar el modelo complejo con el modelo interpretable. Si el R cuadrado está cerca de 0 (= SSE alto), entonces el modelo interpretable no puede explicar el modelo de caja negra.
Ten en cuenta que no hemos hablado sobre el rendimiento del modelo del modelo de caja negra subyacente, es decir, qué tan bueno o malo se desempeña al predecir el resultado real. El rendimiento del modelo de caja negra no juega un papel en el entrenamiento del modelo sustituto. La interpretación del modelo sustituto sigue siendo válida porque hace declaraciones sobre el modelo y no sobre el mundo real. Pero, por supuesto, la interpretación del modelo sustituto se vuelve irrelevante si el modelo de caja negra es malo, porque entonces el modelo de caja negra en sí es irrelevante.
También podríamos construir un modelo sustituto basado en un subconjunto de los datos originales o volver a ponderar las instancias. De esta manera, cambiamos la distribución de la entrada del modelo sustituto, lo que cambia el enfoque de la interpretación (entonces ya no es realmente global). Si ponderamos los datos localmente por una instancia específica de los datos (cuanto más cercanas sean las instancias a la instancia seleccionada, mayor será su peso), obtendremos un modelo sustituto local que puede explicar la predicción individual de la instancia. Lee más sobre modelos locales en el siguiente capítulo.
5.6.2 Ejemplo
Para demostrar los modelos sustitutos, consideramos un problema de clasificación, predecimos la probabilidad de cáncer cervical con un random forest. Nuevamente, entrenamos un árbol de decisión con el conjunto de datos original, pero con la predicción del random forest como resultado, en lugar de las clases reales (sanas versus cáncer) de los datos.
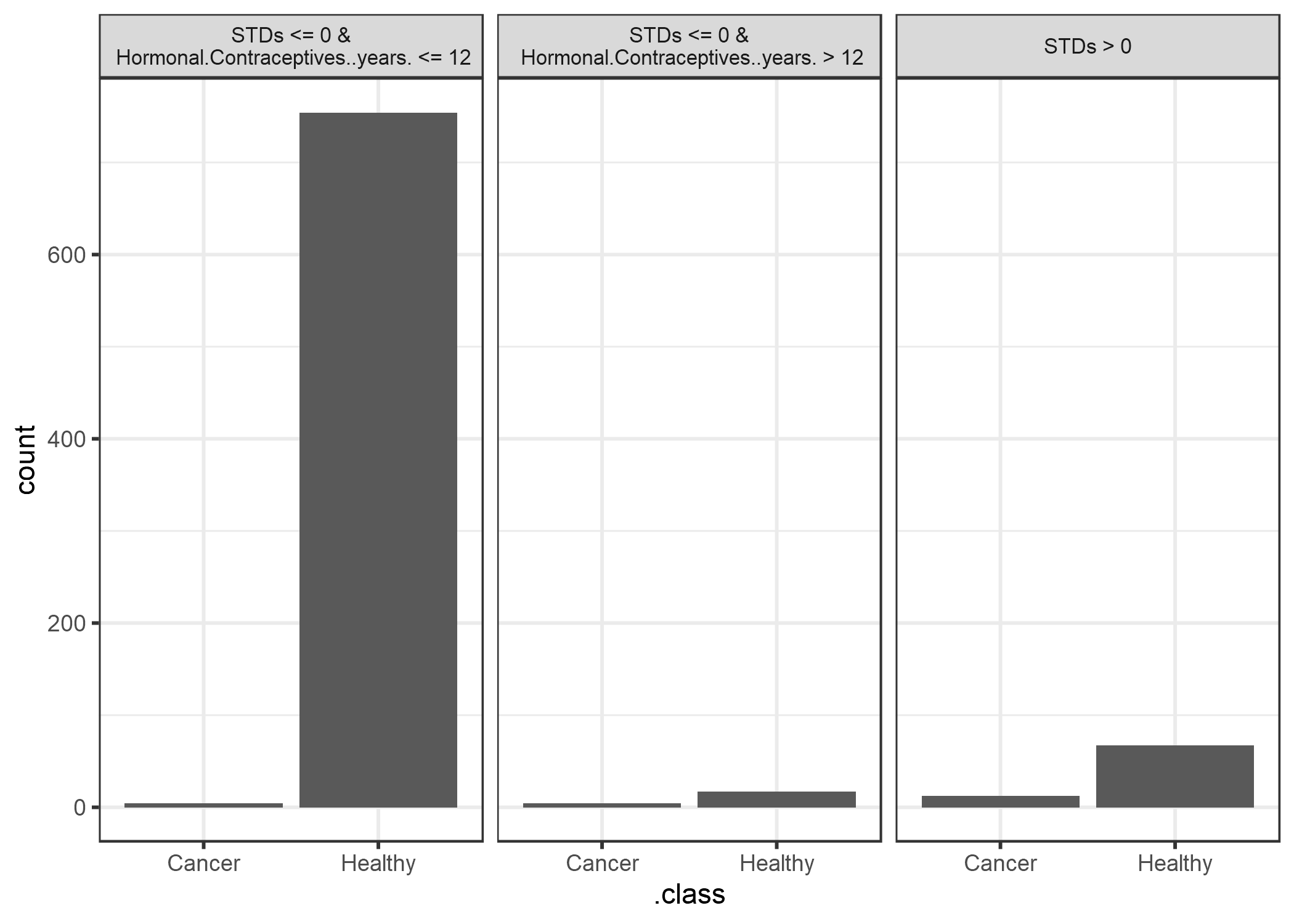
FIGURA 5.31: Los nodos terminales de un árbol sustituto que se aproximan a las predicciones de un random forest entrenado en el conjunto de datos de cáncer cervical. En los nodos muestra la frecuencia de las clasificaciones de los modelos de caja negra en los nodos.
El modelo sustituto tiene un R cuadrado (explica la varianza) de 0.2, lo que significa que no se aproxima bien al random forest y no debemos sobreinterpretar el árbol cuando sacar conclusiones sobre el modelo complejo.
Nota del traductor: la versión original ejemplifica además con un problema de regresión que no se incluye en la traducción.
5.6.3 Ventajas
El método del modelo sustituto es flexible: Se puede usar cualquier modelo del capítulo de modelos interpretables. Esto también significa que puedes intercambiar no solo el modelo interpretable, sino también el modelo de caja negra subyacente. Supón que crea un modelo complejo y lo explica a los diferentes equipos de tu empresa. Un equipo está familiarizado con los modelos lineales, el otro equipo puede entender los árboles de decisión. Puedes entrenar dos modelos sustitutos (modelo lineal y árbol de decisión) para el modelo de caja negra original y ofrecer dos tipos de explicaciones. Si encuentras un modelo de caja negra con mejor rendimiento, no tienes que cambiar tu método de interpretación, ya que puedes usar la misma clase de modelos sustitutos.
Yo diría que el enfoque es muy intuitivo y directo. Esto significa que es fácil de implementar, pero también fácil de explicar a personas que no están familiarizadas con la ciencia de datos o el aprendizaje automático.
Con la medida de R cuadrado, podemos medir fácilmente qué tan buenos son nuestros modelos sustitutos para aproximar las predicciones de la caja negra.
5.6.4 Desventajas
Debes tener en cuenta que extraes conclusiones sobre el modelo y no sobre los datos, ya que el modelo sustituto nunca ve el resultado real.
No está claro cuál es el mejor corte del R2 para estar seguro de que el modelo sustituto está lo suficientemente cerca del modelo de caja negra. ¿80% de la varianza explicada? 50%? 99%?
Podemos medir qué tan cerca está el modelo sustituto del modelo de caja negra. Supongamos que no estamos muy cerca, pero lo suficientemente cerca. Podría suceder que el modelo interpretable sea muy cercano para un subconjunto del conjunto de datos, pero ampliamente divergente para otro subconjunto. En este caso, la interpretación para el modelo simple no sería igualmente buena para todos los puntos de datos.
El modelo interpretable que elijas como sustituto viene con todas sus ventajas y desventajas.
Algunas personas argumentan que, en general, no existen modelos intrínsecamente interpretables (incluso modelos lineales y árboles de decisión) y que incluso sería peligroso tener una ilusión de interpretabilidad. Si compartes esta opinión, entonces este método no es para tí.
5.6.5 Software
Usé el paquete iml R para los ejemplos.
Si puedes entrenar un modelo de aprendizaje automático, entonces deberías poder implementar modelos sustitutos usted mismo.
Simplemente entrena un modelo interpretable para predecir las predicciones del modelo de caja negra.